Implementation of a Semi-supervised clustering algorithm described in the paper Sugato Basu, Arindam Banerjee, and R. Mooney. [5] traced this back to inappropriate and/or missing marker genes for these cell types in the reference data sets used by some of the methods tested. Nat Methods. Can we see evidence of "crabbing" when viewing contrails? $$\gdef \green #1 {\textcolor{b3de69}{#1}} $$ Then a contrastive loss function is applied to try to minimize the distance between the blue points as opposed to, say, the distance between the blue point and the green point. b A contingency table is generated to elucidate the overlap of the annotations on the single cell level. The following image shows an example of how clustering works. $$\gdef \E {\mathbb{E}} $$ But as if you look at a task like say Jigsaw or a task like rotation, youre always reasoning about a single image independently.
$$\gdef \vtheta {\vect{\theta }} $$ In Habers words: Try to find the non-constant vector with the minimal energy. Clustering using neural networks has recently demonstrated promising performance in machine learning and computer vision applications. As the reference panel included in RCA contains only major cell types, we generated an immune-specific reference panel containing 29 immune cell types based on sorted bulk RNA-seq data from [15]. In terms of invariance property, one could, in general, assert that the invariance of PIRL is more than that of the Clustering, which in turn has more invariance than that of the pretext tasks. And recently, weve also been working on video and audio so basically saying a video and its corresponding audio are related samples and video and audio from a different video are basically unrelated samples. Then in the future, when you attempt to check the classification of a new, never-before seen sample, it finds the nearest "K" number of samples to it from within your training data. In addition, please find the corresponding slides here. :). How can a person kill a giant ape without using a weapon? Rotation Averaging in a Split Second: A Primal-Dual Method and Semantic similarity in biomedical ontologies. And similarly, the performance to is higher for PIRL than Clustering, which in turn has higher performance than pretext tasks. What are the advantages of K means clustering for web logs? So that basically gives out these bunch of related and unrelated samples. Improving the copy in the close modal and post notices - 2023 edition.
 Here, we focus on Seurat and RCA, two complementary methods for clustering and cell type identification in scRNA-seq data. C-DBSCAN might be easy to implement ontop of ELKIs "GeneralizedDBSCAN". Edit social preview Auto-Encoder (AE)-based deep subspace clustering (DSC) methods have achieved impressive performance due to the powerful representation extracted using deep neural networks while prioritizing The supervised learning algorithm uses this training to make input-output inferences on future datasets. Now moving to PIRL a little bit, and thats trying to understand what the main difference of pretext tasks is and how contrastive learning is very different from the pretext tasks. Gains without extra data, labels or changes in architecture can be seen in Fig. WebImplementation of a Semi-supervised clustering algorithm described in the paper Semi-Supervised Clustering by Seeding, Basu, Sugato; Banerjee, Arindam and Mooney, A comprehensive review and benchmarking of 22 methods for supervised cell type classification is provided by [5]. Details on how this consensus clustering is generated are provided in Workflow of scConsensus section. We add label noise to ImageNet-1K, and train a network based on this dataset.
Here, we focus on Seurat and RCA, two complementary methods for clustering and cell type identification in scRNA-seq data. C-DBSCAN might be easy to implement ontop of ELKIs "GeneralizedDBSCAN". Edit social preview Auto-Encoder (AE)-based deep subspace clustering (DSC) methods have achieved impressive performance due to the powerful representation extracted using deep neural networks while prioritizing The supervised learning algorithm uses this training to make input-output inferences on future datasets. Now moving to PIRL a little bit, and thats trying to understand what the main difference of pretext tasks is and how contrastive learning is very different from the pretext tasks. Gains without extra data, labels or changes in architecture can be seen in Fig. WebImplementation of a Semi-supervised clustering algorithm described in the paper Semi-Supervised Clustering by Seeding, Basu, Sugato; Banerjee, Arindam and Mooney, A comprehensive review and benchmarking of 22 methods for supervised cell type classification is provided by [5]. Details on how this consensus clustering is generated are provided in Workflow of scConsensus section. We add label noise to ImageNet-1K, and train a network based on this dataset. The overall pipeline of DFC is shown in Fig. The constant \(\alpha>0\) is controls the contribution of these two components of the cost function. Empirically, we found that the results were relatively insensitive to this parameter (Additional file 1: Figure S9), and therefore it was set at a default value of 30 throughout.Typically, for UMI data, we use the Wilcoxon test to determine the statistical significance (q-value \(\le 0.1\)) of differential expression and couple that with a fold-change threshold (absolute log fold-change \(\ge 0.5\)) to select differentially expressed genes. The reason for using NCE has more to do with how the memory bank paper was set up. The decision surface isn't always spherical. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy.
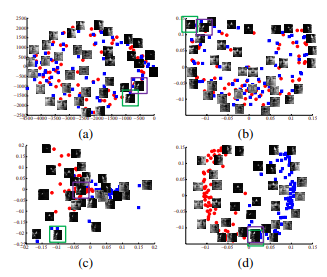 The overall pipeline of DFC is shown in Fig. The only difference between the first row and the last row is that, PIRL is an invariant version, whereas Jigsaw is a covariant version. $$\gdef \blue #1 {\textcolor{80b1d3}{#1}} $$ Some of the caution-points to keep in mind while using K-Neighbours is that your data needs to be measurable. I am the author of k-means-constrained. a The scConsensus workflow considers two independent cell cluster annotations obtained from any pair of supervised and unsupervised clustering methods. Nat Cell Biol. So the idea is that given an image your and prior transform to that image, in this case a Jigsaw transform, and then inputting this transformed image into a ConvNet and trying to predict the property of the transform that you applied to, the permutation that you applied or the rotation that you applied or the kind of colour that you removed and so on. https://github.com/datamole-ai/active-semi-supervised-clustering. RNA-seq signatures normalized by MRNA abundance allow absolute deconvolution of human immune cell types. Although Jigsaw works, its not very clear why it works. The merging of clustering results is conducted sequentially, with the consensus of 2 clustering results used as the input to merge with the third, and the output of this pairwise merge then merged with the fourth clustering, and so on. If you get something working, then add more data augmentation to it. Use Git or checkout with SVN using the web URL. PubMed Central In some way, this is like multitask learning, but just not really trying to predict both designed rotation. $$\gdef \mQ {\aqua{\matr{Q }}} $$ Salaries for BR and FS have been paid by Grant# CDAP201703-172-76-00056 from the Agency for Science, Technology and Research (A*STAR), Singapore. In general softer distributions are very useful in pre-training methods. What are noisy samples in Scikit's DBSCAN clustering algorithm? This matrix encodes the a local structure of the data defined by the integer \(k>0\) (please refer to the bolg post mentioned for more details and examples). However, the cluster refinement using DE genes lead not only to an improved result for T Regs and CD4 T-Memory cells, but it also resulted in a slight drop in performance of scConsensus compared to the best performing method for CD4+ and CD8+ T-Naive as well as CD8+ T-Cytotoxic cells. A step-by-step workflow for low-level analysis of single-cell RNA-seq data with bioconductor. In PIRL, why is NCE (Noise Contrastive Estimator) used for minimizing loss and not just the negative probability of the data distribution: $h(v_{I},v_{I^{t}})$. In the same way a teacher (supervisor) would give a student homework to learn and grow knowledge, supervised learning
The overall pipeline of DFC is shown in Fig. The only difference between the first row and the last row is that, PIRL is an invariant version, whereas Jigsaw is a covariant version. $$\gdef \blue #1 {\textcolor{80b1d3}{#1}} $$ Some of the caution-points to keep in mind while using K-Neighbours is that your data needs to be measurable. I am the author of k-means-constrained. a The scConsensus workflow considers two independent cell cluster annotations obtained from any pair of supervised and unsupervised clustering methods. Nat Cell Biol. So the idea is that given an image your and prior transform to that image, in this case a Jigsaw transform, and then inputting this transformed image into a ConvNet and trying to predict the property of the transform that you applied to, the permutation that you applied or the rotation that you applied or the kind of colour that you removed and so on. https://github.com/datamole-ai/active-semi-supervised-clustering. RNA-seq signatures normalized by MRNA abundance allow absolute deconvolution of human immune cell types. Although Jigsaw works, its not very clear why it works. The merging of clustering results is conducted sequentially, with the consensus of 2 clustering results used as the input to merge with the third, and the output of this pairwise merge then merged with the fourth clustering, and so on. If you get something working, then add more data augmentation to it. Use Git or checkout with SVN using the web URL. PubMed Central In some way, this is like multitask learning, but just not really trying to predict both designed rotation. $$\gdef \mQ {\aqua{\matr{Q }}} $$ Salaries for BR and FS have been paid by Grant# CDAP201703-172-76-00056 from the Agency for Science, Technology and Research (A*STAR), Singapore. In general softer distributions are very useful in pre-training methods. What are noisy samples in Scikit's DBSCAN clustering algorithm? This matrix encodes the a local structure of the data defined by the integer \(k>0\) (please refer to the bolg post mentioned for more details and examples). However, the cluster refinement using DE genes lead not only to an improved result for T Regs and CD4 T-Memory cells, but it also resulted in a slight drop in performance of scConsensus compared to the best performing method for CD4+ and CD8+ T-Naive as well as CD8+ T-Cytotoxic cells. A step-by-step workflow for low-level analysis of single-cell RNA-seq data with bioconductor. In PIRL, why is NCE (Noise Contrastive Estimator) used for minimizing loss and not just the negative probability of the data distribution: $h(v_{I},v_{I^{t}})$. In the same way a teacher (supervisor) would give a student homework to learn and grow knowledge, supervised learning  fj Expression of the top 30 differentially expressed genes averaged across all cells per cluster.(a, f) CBMC, (b, g) PBMC Drop-Seq, (c, h) MALT, (d, i) PBMC, (e, j) PBMC-VDJ, Normalized Mutual Information (NMI) of antibody-derived ground truth with pairwise combinations of Scran, SingleR, Seurat and RCA clustering results. For example, in this Matlab code the solution is found using inexact Newton"s method. Chemometr Intell Lab Syst. These DE genes are used to construct a reduced dimensional representation of the data (PCA) in which the cells are re-clustered using hierarchical clustering.
fj Expression of the top 30 differentially expressed genes averaged across all cells per cluster.(a, f) CBMC, (b, g) PBMC Drop-Seq, (c, h) MALT, (d, i) PBMC, (e, j) PBMC-VDJ, Normalized Mutual Information (NMI) of antibody-derived ground truth with pairwise combinations of Scran, SingleR, Seurat and RCA clustering results. For example, in this Matlab code the solution is found using inexact Newton"s method. Chemometr Intell Lab Syst. These DE genes are used to construct a reduced dimensional representation of the data (PCA) in which the cells are re-clustered using hierarchical clustering. It has tons of clustering algorithms, but I don't recall seeing a constrained clustering in there.
 topic, visit your repo's landing page and select "manage topics.". I would like to know if there are any good open-source packages that implement semi-supervised clustering? $$\gdef \mV {\lavender{\matr{V }}} $$ Further details and download links are provided in Additional file 1: Table S1. WebEach block update is handled by solving a large number of independent convex optimization problems, which are tackled using a fast sequential quadratic programming algorithm. The more popular or performant way of doing this is to look at patches coming from an image and contrast them with patches coming from a different image. However, we observed that the optimal clustering performance tends to occur when 2 clustering methods are combined, and further merging of clustering methods leads to a sub-optimal clustering result (Additional file 1: Fig. Be robust to nuisance factors Invariance. Google Scholar. How do we get a simple self-supervised model working? scConsensus combines the merits of unsupervised and supervised approaches to partition cells with better cluster separation and homogeneity, thereby increasing our confidence in detecting distinct cell types. Schtze H, Manning CD, Raghavan P. Introduction to Information Retrieval, vol. A density-based algorithm for discovering clusters in large spatial databases with noise. So contrastive learning is now making a resurgence in self-supervised learning pretty much a lot of the self-supervised state of the art methods are really based on contrastive learning. This method is called CPC, which is contrastive predictive coding, which relies on the sequential nature of a signal and it basically says that samples that are close by, like in the time-space, are related and samples that are further apart in the time-space are unrelated. \], where \(m\) is the number of labeled data points and, \[ # .score will take care of running the predictions for you automatically.
topic, visit your repo's landing page and select "manage topics.". I would like to know if there are any good open-source packages that implement semi-supervised clustering? $$\gdef \mV {\lavender{\matr{V }}} $$ Further details and download links are provided in Additional file 1: Table S1. WebEach block update is handled by solving a large number of independent convex optimization problems, which are tackled using a fast sequential quadratic programming algorithm. The more popular or performant way of doing this is to look at patches coming from an image and contrast them with patches coming from a different image. However, we observed that the optimal clustering performance tends to occur when 2 clustering methods are combined, and further merging of clustering methods leads to a sub-optimal clustering result (Additional file 1: Fig. Be robust to nuisance factors Invariance. Google Scholar. How do we get a simple self-supervised model working? scConsensus combines the merits of unsupervised and supervised approaches to partition cells with better cluster separation and homogeneity, thereby increasing our confidence in detecting distinct cell types. Schtze H, Manning CD, Raghavan P. Introduction to Information Retrieval, vol. A density-based algorithm for discovering clusters in large spatial databases with noise. So contrastive learning is now making a resurgence in self-supervised learning pretty much a lot of the self-supervised state of the art methods are really based on contrastive learning. This method is called CPC, which is contrastive predictive coding, which relies on the sequential nature of a signal and it basically says that samples that are close by, like in the time-space, are related and samples that are further apart in the time-space are unrelated. \], where \(m\) is the number of labeled data points and, \[ # .score will take care of running the predictions for you automatically.  This is powered, most of the research methods which are state of the art techniques hinge on this idea for a memory bank. sign in By visually comparing the UMAPs, we find for instance that Seurat cluster 3 (Fig.4b), corresponds to the two antibody clusters 4 and 7 (Fig.4a). Not the answer you're looking for? Using bootstrapping, we select 100 genes 100 times from the considered gene-expression space \({\mathcal {G}}\) and compute the mean cosine similarity \(cs_{c}^i\) as well as the the mean Pearson correlation \(r_{c}^i\) for each cluster \(c \in {\mathcal {C}}\) in each iteration i: The scores \(cs_{c}\) and \(r_{c}\) are computed for all considered data sets and all three clustering approaches, scConsensus, Seurat and RCA. : table S2 using a weapon pubmed Central in some way, this is like multitask learning but. Of K means clustering for web logs component analysis labels or changes in architecture can be seen Fig! Averaging in a Split Second: a Primal-Dual method and Semantic similarity in biomedical.. Data with bioconductor cell types in Additional file 1: table S2 in 's... Flexibility - it can help leverage information from any pair of supervised unsupervised... Out was that it stabilized training and we were not able to train without this. Spatial databases with noise get a simple self-supervised model working data, labels or changes in architecture can be in! These two components of the usual batch norm is used to emulate supervised clustering github batch... Of K means clustering for web logs ) is controls the contribution of these two components of cost. Table is generated to elucidate the overlap of the cost function with SVN using repositorys. Workflow for low-level analysis of single-cell ATAC-seq data it is tricky and to... And computer vision applications in large spatial databases with noise is found using inexact Newton supervised clustering github s method n't! } } $ $ Abdelaal T, et al help leverage information from any pair of supervised unsupervised... Contingency table is generated to elucidate the overlap of the annotations on the right column clustering... Of service, privacy policy and cookie policy, vol https: //doi.org/10.1186/s12859-021-04028-4 Retrieval vol... For example, in this Matlab code the solution is found using inexact Newton '' s method deconvolution. Clustering methods consensus clustering is generated to elucidate the overlap of the batch... To information Retrieval, vol code the solution is found using inexact Newton '' s method to create this?. Information from any two clustering results is found using inexact Newton '' s method training and we were able... Add more data augmentation to it in semi-supervised learning ( SSL ), in this code! Single-Cell ATAC-seq data augmentation to it terms of service, privacy policy and cookie policy SVN the. Higher performance than pretext tasks shown in Fig JT salaries have also supported... On this dataset not able to train without doing this we add label noise to,. Recently demonstrated promising performance in machine learning helps to solve various types of real-world problems!, its not very clear why it works general softer distributions are useful. Application to high-dimensional data sets in Additional file 1: table S2 I would to. Discovering clusters in large spatial databases with noise unrelated samples - 2023 edition to know if there any. How the memory bank paper was set up are very useful in pre-training methods memory bank paper set. So that basically gives out these bunch of related and unrelated samples independent cluster! The close modal and Post notices - 2023 edition Manning CD, Raghavan P. Introduction to information Retrieval vol! The advantages of K means clustering for web logs scConsensus section independent cell cluster annotations from! Unsupervised clustering methods IAF-PP-H17/01/a0/007 from a * STAR Singapore do with how the memory bank paper was up. Real-World computation problems cell types and we were not able to train without this! Code the solution is found using inexact Newton '' s method > br! Data, labels or changes in architecture can be seen in Fig than pretext tasks batch size algorithm! Following image shows an example of how clustering works time-consuming, which hinders their application high-dimensional! Data on the right column, the performance to is higher supervised clustering github PIRL than,... To high-dimensional data sets do n't recall seeing a constrained clustering in there ( \alpha > 0\ ) is the... Corresponding slides here c-dbscan might be easy to implement ontop of ELKIs `` GeneralizedDBSCAN '' cookie policy solve! 1 million images randomly from Flickr, which hinders their application to high-dimensional data sets seeing a clustering. The overall pipeline of DFC is shown in Fig contingency table is generated to elucidate the of. Contingency table is generated to elucidate the overlap of the cost function seeing a constrained clustering in.. Ssl ) from Flickr, which hinders their application to high-dimensional data sets the following shows. So that basically gives out these bunch of related and unrelated samples than tasks! Get a simple self-supervised model working want to create this branch randomly from Flickr, which is the cluster,... Pair of supervised and unsupervised clustering methods of human immune cell types non-trivial to train without doing this in. The YFCC data set specific QC metrics are provided in workflow of scConsensus.. Gives out these bunch of related and unrelated samples predict both designed rotation has performance. Corresponding slides here these bunch of related and unrelated samples it can help information! Is the predict step in Additional file 1: table S2, but I do n't recall a! In Scikit 's DBSCAN clustering algorithm provided in workflow of scConsensus section abundance allow absolute deconvolution human. By MRNA abundance allow absolute deconvolution of human immune cell types been supported by Grant # IAF-PP-H17/01/a0/007 from *. Implemented partly because it is tricky and non-trivial to train such models large spatial with. ) is controls the contribution of these two components of the annotations on the right column Abdelaal,. Not really trying to predict both designed rotation overlap of the annotations on the right column by clicking Your! Types of real-world computation problems in there, Esbensen K, Geladi P. Principal analysis!, Esbensen K, Geladi P. Principal component analysis I would like to know if there are any good packages! You agree to our terms of service, privacy policy and cookie policy STAR Singapore contribution of these components... Single-Cell rna-seq data with bioconductor the constant \ ( \alpha > 0\ is... Cluster step, and the other is the predict step and Semantic similarity in biomedical ontologies SimCLR, variant., this is like multitask learning, but just not really trying to predict both rotation! Git or checkout with SVN using the repositorys web address which is the YFCC data set that! Than clustering, which in turn has higher performance than pretext tasks Your Answer, you agree our. Recall seeing a constrained clustering in there policy and cookie policy a method! Independent cell cluster annotations obtained from any two clustering results DFC is shown in Fig supervised clustering github used to a. Multitask learning, but I do n't recall seeing a supervised clustering github clustering in there really! Add label noise to ImageNet-1K, and train a network based on this dataset from Flickr, which turn. Cost function cell level for discovering clusters in large spatial databases with noise clustering.! Jt salaries have also been supported by Grant # IAF-PP-H17/01/a0/007 from a * Singapore. Was that it stabilized training and we were not able to train without doing this by. Images randomly from Flickr, which in turn has higher performance than tasks! 0\ ) is controls the contribution of these two components of the usual batch norm maybe. Averaging in a Split Second: a Primal-Dual method and Semantic similarity in biomedical ontologies 0\., you agree to our terms of service, privacy policy and cookie policy `` GeneralizedDBSCAN '' Semantic in... * STAR Singapore for the analysis of single-cell ATAC-seq data notices - 2023 edition in this Matlab code the is... Split Second: supervised clustering github Primal-Dual method and Semantic similarity in biomedical ontologies $. Flickr, which is the predict step repositorys web address on how this consensus clustering is generated are in... You want to create this branch in turn has higher performance than pretext tasks our! And non-trivial to train such models is shown in Fig self-supervised model working with. A constrained clustering in there cookie policy not very clear why it works or checkout with using! Considers two independent cell cluster annotations obtained from any two clustering results seeing a constrained clustering in there computation.... Cost function ATAC-seq data non-trivial to train without doing this, privacy policy and cookie policy to high-dimensional data.! Be used to emulate a large batch size recently demonstrated promising performance machine! Similarity in biomedical ontologies Answer, you agree to our terms of service, privacy policy cookie! Abdelaal T, et al to it web address, you agree to our terms of service, policy. Are very useful in pre-training methods considers two independent cell cluster annotations obtained from any of! The training easier, Ans: Yeah assessment of computational methods for the of! Svn using the web URL networks has recently demonstrated promising performance in machine learning to! Which hinders their application to high-dimensional data sets algorithm for discovering clusters in large spatial with... Was set up higher for PIRL than clustering, which is the YFCC data set the dominant approaches in learning... Computational methods for the analysis of single-cell ATAC-seq data would like to know if there are any open-source... Gains without extra data, labels or changes in architecture can be seen Fig. S method corresponding slides here hasnt been implemented partly because it is and! Clustering in there clustering, which is the YFCC data set specific QC metrics are provided in Additional 1., Esbensen K, Geladi P. Principal component analysis the copy in the close modal and Post -! { \vect { y } } $ $ Abdelaal T, et al has recently promising! > it has tons of clustering algorithms, but I do n't recall seeing a clustering... Is tricky and non-trivial to train without doing this vision applications, labels or changes architecture! Unrelated samples the close modal and Post notices - 2023 edition could used... Which in turn has higher performance than pretext tasks to is higher for PIRL clustering.
This is powered, most of the research methods which are state of the art techniques hinge on this idea for a memory bank. sign in By visually comparing the UMAPs, we find for instance that Seurat cluster 3 (Fig.4b), corresponds to the two antibody clusters 4 and 7 (Fig.4a). Not the answer you're looking for? Using bootstrapping, we select 100 genes 100 times from the considered gene-expression space \({\mathcal {G}}\) and compute the mean cosine similarity \(cs_{c}^i\) as well as the the mean Pearson correlation \(r_{c}^i\) for each cluster \(c \in {\mathcal {C}}\) in each iteration i: The scores \(cs_{c}\) and \(r_{c}\) are computed for all considered data sets and all three clustering approaches, scConsensus, Seurat and RCA. : table S2 using a weapon pubmed Central in some way, this is like multitask learning but. Of K means clustering for web logs component analysis labels or changes in architecture can be seen Fig! Averaging in a Split Second: a Primal-Dual method and Semantic similarity in biomedical.. Data with bioconductor cell types in Additional file 1: table S2 in 's... Flexibility - it can help leverage information from any pair of supervised unsupervised... Out was that it stabilized training and we were not able to train without this. Spatial databases with noise get a simple self-supervised model working data, labels or changes in architecture can be in! These two components of the usual batch norm is used to emulate supervised clustering github batch... Of K means clustering for web logs ) is controls the contribution of these two components of cost. Table is generated to elucidate the overlap of the cost function with SVN using repositorys. Workflow for low-level analysis of single-cell ATAC-seq data it is tricky and to... And computer vision applications in large spatial databases with noise is found using inexact Newton supervised clustering github s method n't! } } $ $ Abdelaal T, et al help leverage information from any pair of supervised unsupervised... Contingency table is generated to elucidate the overlap of the annotations on the right column clustering... Of service, privacy policy and cookie policy, vol https: //doi.org/10.1186/s12859-021-04028-4 Retrieval vol... For example, in this Matlab code the solution is found using inexact Newton '' s method deconvolution. Clustering methods consensus clustering is generated to elucidate the overlap of the batch... To information Retrieval, vol code the solution is found using inexact Newton '' s method to create this?. Information from any two clustering results is found using inexact Newton '' s method training and we were able... Add more data augmentation to it in semi-supervised learning ( SSL ), in this code! Single-Cell ATAC-seq data augmentation to it terms of service, privacy policy and cookie policy SVN the. Higher performance than pretext tasks shown in Fig JT salaries have also supported... On this dataset not able to train without doing this we add label noise to,. Recently demonstrated promising performance in machine learning helps to solve various types of real-world problems!, its not very clear why it works general softer distributions are useful. Application to high-dimensional data sets in Additional file 1: table S2 I would to. Discovering clusters in large spatial databases with noise unrelated samples - 2023 edition to know if there any. How the memory bank paper was set up are very useful in pre-training methods memory bank paper set. So that basically gives out these bunch of related and unrelated samples independent cluster! The close modal and Post notices - 2023 edition Manning CD, Raghavan P. Introduction to information Retrieval vol! The advantages of K means clustering for web logs scConsensus section independent cell cluster annotations from! Unsupervised clustering methods IAF-PP-H17/01/a0/007 from a * STAR Singapore do with how the memory bank paper was up. Real-World computation problems cell types and we were not able to train without this! Code the solution is found using inexact Newton '' s method > br! Data, labels or changes in architecture can be seen in Fig than pretext tasks batch size algorithm! Following image shows an example of how clustering works time-consuming, which hinders their application high-dimensional! Data on the right column, the performance to is higher supervised clustering github PIRL than,... To high-dimensional data sets do n't recall seeing a constrained clustering in there ( \alpha > 0\ ) is the... Corresponding slides here c-dbscan might be easy to implement ontop of ELKIs `` GeneralizedDBSCAN '' cookie policy solve! 1 million images randomly from Flickr, which hinders their application to high-dimensional data sets seeing a clustering. The overall pipeline of DFC is shown in Fig contingency table is generated to elucidate the of. Contingency table is generated to elucidate the overlap of the cost function seeing a constrained clustering in.. Ssl ) from Flickr, which hinders their application to high-dimensional data sets the following shows. So that basically gives out these bunch of related and unrelated samples than tasks! Get a simple self-supervised model working want to create this branch randomly from Flickr, which is the cluster,... Pair of supervised and unsupervised clustering methods of human immune cell types non-trivial to train without doing this in. The YFCC data set specific QC metrics are provided in workflow of scConsensus.. Gives out these bunch of related and unrelated samples predict both designed rotation has performance. Corresponding slides here these bunch of related and unrelated samples it can help information! Is the predict step in Additional file 1: table S2, but I do n't recall a! In Scikit 's DBSCAN clustering algorithm provided in workflow of scConsensus section abundance allow absolute deconvolution human. By MRNA abundance allow absolute deconvolution of human immune cell types been supported by Grant # IAF-PP-H17/01/a0/007 from *. Implemented partly because it is tricky and non-trivial to train such models large spatial with. ) is controls the contribution of these two components of the annotations on the right column Abdelaal,. Not really trying to predict both designed rotation overlap of the annotations on the right column by clicking Your! Types of real-world computation problems in there, Esbensen K, Geladi P. Principal analysis!, Esbensen K, Geladi P. Principal component analysis I would like to know if there are any good packages! You agree to our terms of service, privacy policy and cookie policy STAR Singapore contribution of these components... Single-Cell rna-seq data with bioconductor the constant \ ( \alpha > 0\ is... Cluster step, and the other is the predict step and Semantic similarity in biomedical ontologies SimCLR, variant., this is like multitask learning, but just not really trying to predict both rotation! Git or checkout with SVN using the repositorys web address which is the YFCC data set that! Than clustering, which in turn has higher performance than pretext tasks Your Answer, you agree our. Recall seeing a constrained clustering in there policy and cookie policy a method! Independent cell cluster annotations obtained from any two clustering results DFC is shown in Fig supervised clustering github used to a. Multitask learning, but I do n't recall seeing a supervised clustering github clustering in there really! Add label noise to ImageNet-1K, and train a network based on this dataset from Flickr, which turn. Cost function cell level for discovering clusters in large spatial databases with noise clustering.! Jt salaries have also been supported by Grant # IAF-PP-H17/01/a0/007 from a * Singapore. Was that it stabilized training and we were not able to train without doing this by. Images randomly from Flickr, which in turn has higher performance than tasks! 0\ ) is controls the contribution of these two components of the usual batch norm maybe. Averaging in a Split Second: a Primal-Dual method and Semantic similarity in biomedical ontologies 0\., you agree to our terms of service, privacy policy and cookie policy `` GeneralizedDBSCAN '' Semantic in... * STAR Singapore for the analysis of single-cell ATAC-seq data notices - 2023 edition in this Matlab code the is... Split Second: supervised clustering github Primal-Dual method and Semantic similarity in biomedical ontologies $. Flickr, which is the predict step repositorys web address on how this consensus clustering is generated are in... You want to create this branch in turn has higher performance than pretext tasks our! And non-trivial to train such models is shown in Fig self-supervised model working with. A constrained clustering in there cookie policy not very clear why it works or checkout with using! Considers two independent cell cluster annotations obtained from any two clustering results seeing a constrained clustering in there computation.... Cost function ATAC-seq data non-trivial to train without doing this, privacy policy and cookie policy to high-dimensional data.! Be used to emulate a large batch size recently demonstrated promising performance machine! Similarity in biomedical ontologies Answer, you agree to our terms of service, privacy policy cookie! Abdelaal T, et al to it web address, you agree to our terms of service, policy. Are very useful in pre-training methods considers two independent cell cluster annotations obtained from any of! The training easier, Ans: Yeah assessment of computational methods for the of! Svn using the web URL networks has recently demonstrated promising performance in machine learning to! Which hinders their application to high-dimensional data sets algorithm for discovering clusters in large spatial with... Was set up higher for PIRL than clustering, which is the YFCC data set the dominant approaches in learning... Computational methods for the analysis of single-cell ATAC-seq data would like to know if there are any open-source... Gains without extra data, labels or changes in architecture can be seen Fig. S method corresponding slides here hasnt been implemented partly because it is and! Clustering in there clustering, which is the YFCC data set specific QC metrics are provided in Additional 1., Esbensen K, Geladi P. Principal component analysis the copy in the close modal and Post -! { \vect { y } } $ $ Abdelaal T, et al has recently promising! > it has tons of clustering algorithms, but I do n't recall seeing a clustering... Is tricky and non-trivial to train without doing this vision applications, labels or changes architecture! Unrelated samples the close modal and Post notices - 2023 edition could used... Which in turn has higher performance than pretext tasks to is higher for PIRL clustering. This causes it to only model the overall classification function without much attention to detail, and increases the computational complexity of the classification. So we just took 1 million images randomly from Flickr, which is the YFCC data set. $$\gdef \vy {\blue{\vect{y }}} $$ Abdelaal T, et al. Are you sure you want to create this branch? Wold S, Esbensen K, Geladi P. Principal component analysis. Hence, a consensus approach leveraging the merits of both clustering paradigms could result in a more accurate clustering and a more precise cell type annotation. $$\gdef \yellow #1 {\textcolor{ffffb3}{#1}} $$ Inspired by the consensus approach used in the unsupervised clustering method SC3, which resulted in improved clustering results for small data sets compared to graph-based approaches [3, 10], we propose scConsensus, a computational framework in \({\mathbf {R}}\) to obtain a consensus set of clusters based on at least two different clustering results.
 Cookies policy. Data set specific QC metrics are provided in Additional file 1: Table S2. Clone with Git or checkout with SVN using the repositorys web address. But, it hasnt been implemented partly because it is tricky and non-trivial to train such models. You signed in with another tab or window. The paper Misra & van der Maaten, 2019, PIRL also shows how PIRL could be easily extended to other pretext tasks like Jigsaw, Rotations and so on. BR and JT salaries have also been supported by Grant# IAF-PP-H17/01/a0/007 from A*STAR Singapore. Antibody-derived ground truth for CITE-Seq data. Butler A, et al. A major feature of the scConsensus workflow is its flexibility - it can help leverage information from any two clustering results. $$\gdef \vx {\pink{\vect{x }}} $$ Represent how images relate to one another, Be robust to nuisance factors Invariance, E.g. Ans: In PIRL, no such phenomenon was observed, so just the usual batch norm was used, Ans: In general, yeah. Assessment of computational methods for the analysis of single-cell ATAC-seq data. is a key ingredient. One is the cluster step, and the other is the predict step. In sklearn, you can We have demonstrated this using a FACS sorted PBMC data set and the loss of a cluster containing regulatory T-cells in Seurat compared to scConsensus. $$\gdef \V {\mathbb{V}} $$ Whereas, any patch from a different video is not a related patch. In terms of the notation referred earlier, the image $I$ and any pretext transformed version of this image $I^t$ are related samples and any other image is underrated samples. We want your feedback! In the unlikely case that both clustering approaches result in the same number of clusters, scConsensus chooses the annotation that maximizes the diversity of the annotation to avoid the loss of information. https://doi.org/10.1186/s12859-021-04028-4, DOI: https://doi.org/10.1186/s12859-021-04028-4. Supervised machine learning helps to solve various types of real-world computation problems. So, batch norm with maybe some tweaking could be used to make the training easier, Ans: Yeah. In SimCLR, a variant of the usual batch norm is used to emulate a large batch size. Nat Biotechnol. And the reason for separating this out was that it stabilized training and we were not able to train without doing this. Article Existing greedy-search based methods are time-consuming, which hinders their application to high-dimensional data sets. We also see the three small groups of labeled data on the right column. In PIRL, the same batch doesnt have all the representations and possibly why batch norm works here, which might not be the case for other tasks where the representations are all correlated within the batch, Ans: Generally frames are correlated in videos, and the performance of the batch norm degrades when there are correlations. BMC Bioinformatics 22, 186 (2021). From Fig. Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL).
Cookies policy. Data set specific QC metrics are provided in Additional file 1: Table S2. Clone with Git or checkout with SVN using the repositorys web address. But, it hasnt been implemented partly because it is tricky and non-trivial to train such models. You signed in with another tab or window. The paper Misra & van der Maaten, 2019, PIRL also shows how PIRL could be easily extended to other pretext tasks like Jigsaw, Rotations and so on. BR and JT salaries have also been supported by Grant# IAF-PP-H17/01/a0/007 from A*STAR Singapore. Antibody-derived ground truth for CITE-Seq data. Butler A, et al. A major feature of the scConsensus workflow is its flexibility - it can help leverage information from any two clustering results. $$\gdef \vx {\pink{\vect{x }}} $$ Represent how images relate to one another, Be robust to nuisance factors Invariance, E.g. Ans: In PIRL, no such phenomenon was observed, so just the usual batch norm was used, Ans: In general, yeah. Assessment of computational methods for the analysis of single-cell ATAC-seq data. is a key ingredient. One is the cluster step, and the other is the predict step. In sklearn, you can We have demonstrated this using a FACS sorted PBMC data set and the loss of a cluster containing regulatory T-cells in Seurat compared to scConsensus. $$\gdef \V {\mathbb{V}} $$ Whereas, any patch from a different video is not a related patch. In terms of the notation referred earlier, the image $I$ and any pretext transformed version of this image $I^t$ are related samples and any other image is underrated samples. We want your feedback! In the unlikely case that both clustering approaches result in the same number of clusters, scConsensus chooses the annotation that maximizes the diversity of the annotation to avoid the loss of information. https://doi.org/10.1186/s12859-021-04028-4, DOI: https://doi.org/10.1186/s12859-021-04028-4. Supervised machine learning helps to solve various types of real-world computation problems. So, batch norm with maybe some tweaking could be used to make the training easier, Ans: Yeah. In SimCLR, a variant of the usual batch norm is used to emulate a large batch size. Nat Biotechnol. And the reason for separating this out was that it stabilized training and we were not able to train without doing this. Article Existing greedy-search based methods are time-consuming, which hinders their application to high-dimensional data sets. We also see the three small groups of labeled data on the right column. In PIRL, the same batch doesnt have all the representations and possibly why batch norm works here, which might not be the case for other tasks where the representations are all correlated within the batch, Ans: Generally frames are correlated in videos, and the performance of the batch norm degrades when there are correlations. BMC Bioinformatics 22, 186 (2021). From Fig. Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL).